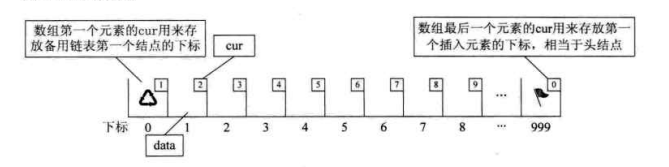
另外我们对数组第一个和最后一个元素作为特殊元素处理,不存数据。我们通常把未被使用的数组元素称为备用链表。而数组第一个元素,即下标为
0 的元素的 cur 就存放备用链表的第一个节点的下标;而数组的最后一个元素的
cur 则存放第一个有数值的元素的下标,
相当于单链表中的头节点作用,当整个链表为空时,则为 0。
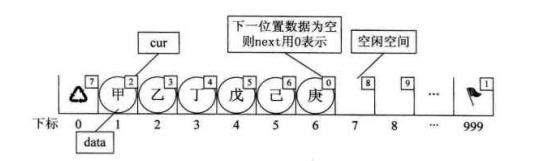
// 若备用空间链表非空,则返回分配的节点下标,否则返回 0 int Malloc_SLL(StaticLinkList space) { int i = space[0].cur; // 当前数组第一个元素的 cur 存的值,就是要返回的第一个备用空闲的下标 if (space[0].cur) space[0].cur = space[i].cur; // 由于要拿出一个分量来使用了,所以我们就得把它的下一个分量用来做备用 return i; }
这段代码有意思,一方面它的作用就是返回一个下标值,这个值就是数组头元素的
cur 存的第一个空闲的下标。从上面的图来看,其实就是 7。
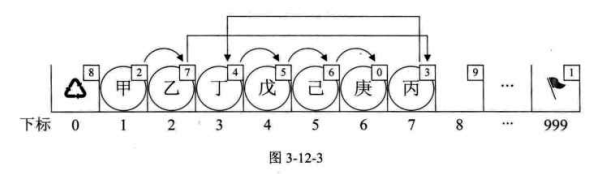
新元素 "丙",想插队是吧?可以,你先悄悄地在队伍最后一排第 7
个游标位置待着,我一会就能帮你搞定。我接着找到了 "乙",告诉它,你的 cur
不是游标 为 3 的 "丁" 了,你把你的下一位的游标改为 7
就可以了。此时再回到 "丙" 那里,说你把你的 cur 改为 3。
就这样,在绝大多数人都不知道的情况下,整个排队的次序发生了改变。
步骤: * 判断下标合法性 * 获取空闲节点的下标 * 写入数据到空闲节点 *
将上面空闲节点的 cur 修改为原 i 位置的 cur * 将写入位置前一个节点的 cur
修改为新节点所在位置
实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
// 在 L 中第 i 个元素之前插入新的数据元素 e Status ListInsert(StaticLinkList L, int i, ElemType e) { int j, k, l; k = MAX_SIZE - 1; // 注意 k 首先是最后一个元素的下标 if (i < 1 || i > ListLength(L) + 1) return ERROR; j = Malloc_SLL(L); // 获得空闲分量的下标 if (j) { L[j].data = e; // 将数据赋值给此分量的 data for (l = 1; l < i - 1; l++) // 找到第 i 个元素之前的位置 k = L[k].cur; L[j].cur = L[k].cur; // 把第 i 个元素之前的 cur 赋值给新元素的 cur L[k].cur = j; // 把新元素的下标赋值给第 i 个元素之前元素的 cur return OK; } return ERROR; }
当我们执行插入语句时,我们的目的是要在 "乙" 和 "丁" 之间插入
"丙"。调用代码时,输入 i 值为 3。
// 删除在 L 中第 i 个数据元素 e Status ListDelete(StaticLinkList L, int i) { int j, k; if (i < 1 || i > ListLength(L)) return ERROR; k = MAX_SIZE - 1; for (j = 0; j <= i - 1; j++) { // 找到第 i 个元素之前的位置 k = L[k].cur; } j = L[k].cur; L[k].cur = L[j].cur; Free_SLL(L, j); return OK; }
// 初始条件:静态链表 L 已存在。操作结果是:返回 L 中数据元素个数 int ListLength(StaticLinkList L) { int j = 0; int i = L[MAXSIZE - 1].cur; while(i) { i = L[i].cur; j++; } return j; }
在进一步讨论之前,我们先解释一下一个类型有某一个方法的具体含义。对每一个具体类型
T,部分方法的接收者就是 T,而其它方法的接收者则是 T 指针。
同时我们对类型 T 的变量直接调用 T
的方法也可以是合法的,只要改变量是可变的,编译器隐式地帮你完成了取地址的操作。但这仅仅是一个语法糖,
类型 T 的方法没有对应的指针 *T
多,所以实现的接口也可能比对应的指针少。
从具体类型出发、提取其共性而得出的每一种分组方式都可以表示为一种接口类型。
与基于类的语言(它们显式地声明了一个类型实现所有的接口)不同的是,在 Go
语言里我们可以在需要时才定义新的抽象和分组,并且不用修改原有类型的定义。
当需要使用另一个作者写的包里的具体类型时,这一点特别有用。当然,还需要这些具体类型在底层是真正有共性的。
类型断言是一个作用在接口值上的操作,写出来类似于
x.(T),其中 x 是一个接口类型的表达式,而 T
是一个类型(称为断言类型)。
类型断言会检查作为操作数的动态类型是否满足指定的断言类型。
这儿有两个可能。首先,如果断言类型 T
是一个具体类型,那么类型断言会检查 x 的动态类型是否就是
T。如果检查成功,类型断言的结果就是 x 的动态值, 类型当然是
T。换句话说,类型断言就是用来从它的操作数中把具体类型的值提取出来的操作。如果检查失败,那么操作崩溃。比如:
1 2 3 4
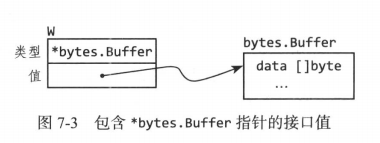
var w io.Writer w = os.Stdout f := w.(*os.File) // 成功:f == os.Stdout c := w.(*bytes.Buffer) // 崩溃:接口持有的是 *os.File,不是 *bytes.Buffer
其次,如果断言类型 T 是一个接口类型,那么类型断言检查 x
的动态类型是否满足
T。如果检查成功,动态值并没有提取出来,结果仍然是一个接口值,
接口值的类型和值部分也没有变更,只是结果的类型为接口类型
T。换句话说,类型断言是一个接口值表达式,从一个接口类型变为拥有另外一套方法的接口类型
(通常方法数量是增多),但保留了接口值中的动态类型和动态值部分。
var ErrNotExist = errors.New("file does not exist") // IsNotExist 返回一个布尔值,该值表明错误是否代表文件或者目录不存在 // report that a file or directory does not exist. It is satisfied by // ErrNotExist 和其它一些系统调用错误会返回 true funcIsNotExist(err error)bool { if pe, ok := err.(*PathError); ok { err = pe.Err } return err == syscall.ENOENT || err == ErrNotExist }
funcmain() { var i interface{} student := Student{Name: "golang"} i = test(student) //fmt.Println(i.Name) // i.Name undefined (type interface {} is interface with no methods) fmt.Println(i.(Student).Name) // 我们知道具体类型
// 如果不知道具体类型,可以按照下面的方式判断 // ok 为 true 说明 i 是 Student 类型,否则不是 Student 类型 if j, ok := i.(Student); ok { fmt.Println(j.Name) }
// 下面的 ok 为 false var ii interface{} ii = test(ii) if v, ok := ii.(Student); ok { fmt.Println(v.Name) } else { fmt.Println("ii is not Student") } }